4. Tumbleweed
Considering the trade-offs associated with enterprise CDC solutions and the complexity of building a DIY alternative, Tumbleweed recognized a gap in the available options for an end-to-end log-based CDC implementation of the outbox pattern.
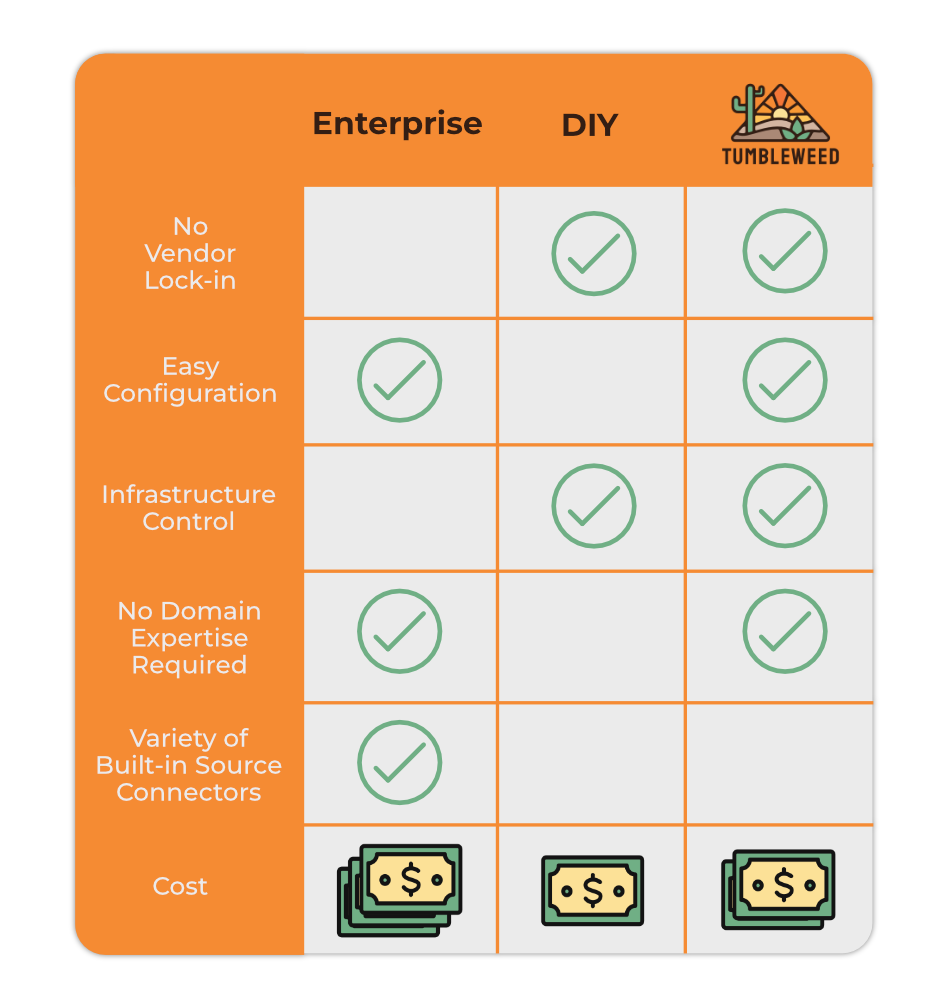
4.1 What is Tumbleweed?
Tumbleweed is an open-source, user-friendly framework designed specifically for teams that use microservices and want to sync data between those services using log-based CDC and the outbox pattern. It works as a drop-in solution to an existing or newly created microservice architecture. A simple CLI application is used to automatically deploy a self-hosted Tumbleweed pipeline to Amazon Web Services (AWS). Tumbleweed provides an intuitive UI that abstracts away the complexities of outbox table creation, configuring message broker and CDC tools, setting up source and sink connectors, defining consumers and subscribing them to event categories. Tumbleweed allows for an intuitive and straightforward approach, integrable within distributed architectures in minutes.
4.2 Tumbleweed Implementation
4.2.1 Tumbleweed Architecture
Tumbleweed integrates and containerizes a variety of open-source frameworks and tools, along with a custom TypeScript backend API into an AWS deployable cluster.
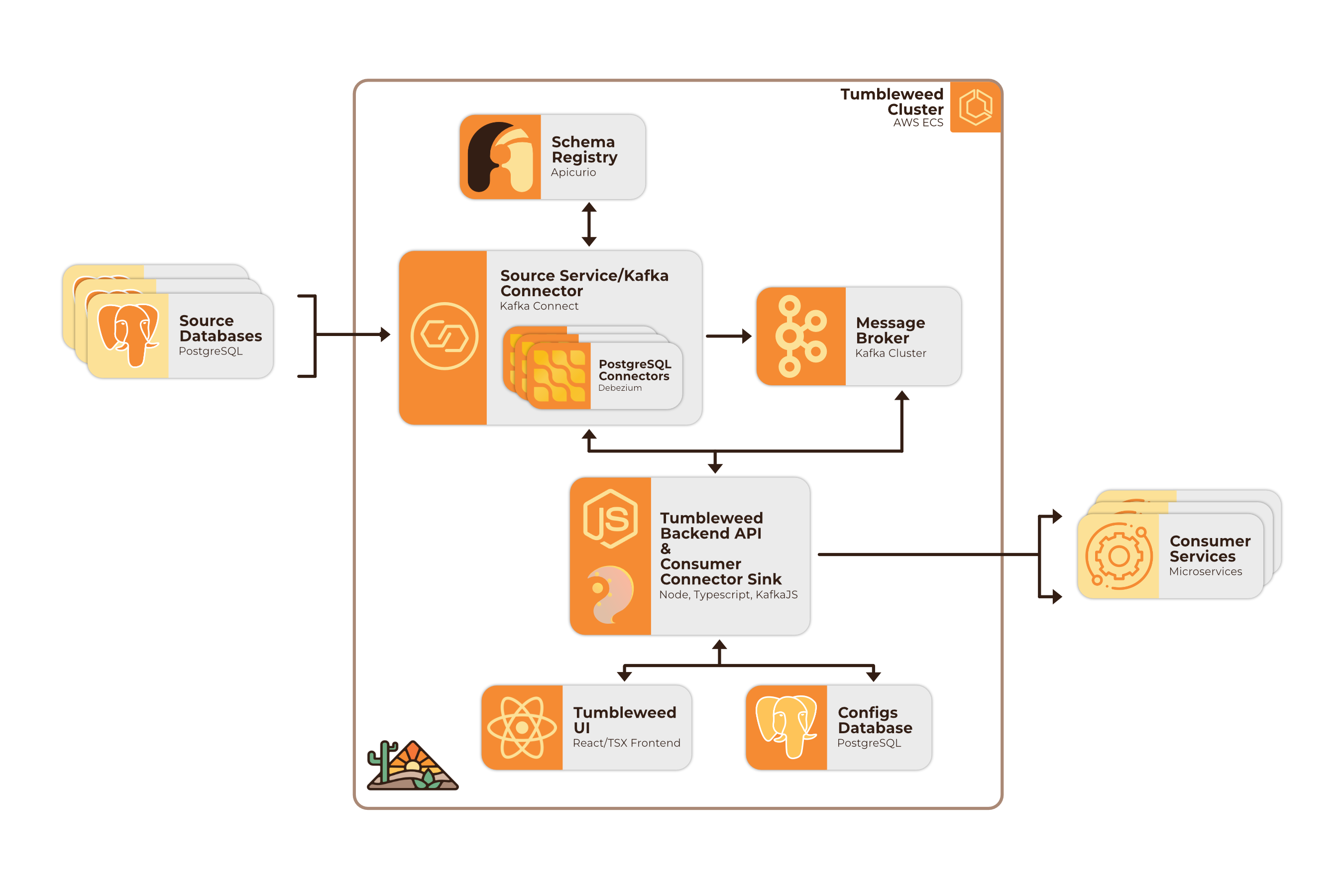
In order to understand how Tumbleweed functions, it's necessary to examine some of these technologies more in depth.
4.2.2 Apache Kafka
A key element of an event driven architecture for decoupled microservices is a message broker or event stream processing platform. Such a platform must reliably ingest large volumes of data from source services and stream it to consumer services. Such a platform is not a trivial technology, especially when built for scalability. Thus we needed to find something battle-tested and heavy-duty. We looked at several open-source options, such as Apache Flink and Apache Pulsar, but found that Apache Kafka was the one that most fit our needs. Kafka has a wide user base, including both large enterprises and smaller scale DIY project users. Because of this, there are many online resources for understanding and using Kafka in a variety of stream processing contexts. Most importantly, a number of robust open-source CDC technologies such as Debezium and Kafka Connect have strong support for Kafka use cases.
Kafka is a distributed, log-based message broker designed for massive real-time data streaming. Kafka centralizes data transmission with a cluster of brokers and their controllers, allowing greater fault tolerance and data durability 1. Producer services send records to the brokers and Kafka appends these records to various write-ahead log "topics". Consumer services then subscribe to specific "topics" in order to get the data that they need 2. A producer can produce one or many topics regardless of available consumers, and a consumer can subscribe to one or many topics from one or more producers. This approach allows for decoupling of producer and consumer services.
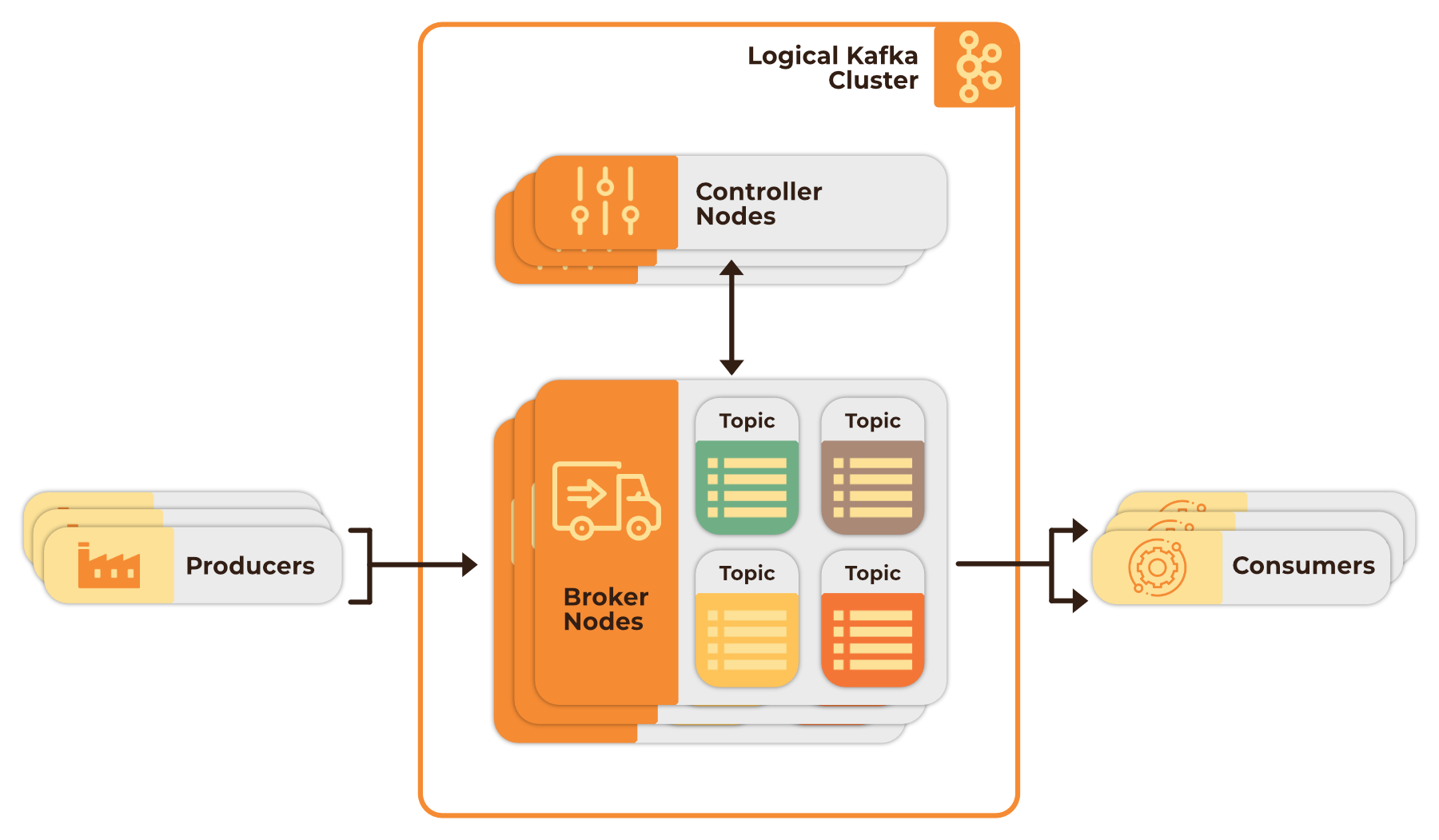
Kafka is the backbone of Tumbleweed. We use a multi-node Kafka cluster for fault tolerance and high throughput. Although Kafka configuration and set-up can be complicated, once configured, Kafka abstracts away much of the complexities of stream processing and message brokering. Many enterprise solutions and large companies also rely on Kafka for their services; LinkedIn leverages Kafka to process upwards of 7 trillion messages per day 3.
4.2.3 Kafka Connect and Debezium
While Kafka solved much of our data streaming needs, we needed a way to get the data from producer services to Kafka itself. This is where Kafka Connect and Debezium came into play.
Kafka Connect allows for transmission between Kafka and external systems via self-built or predefined connectors: Source connectors can ingest data from external producer systems into Kafka topics and sink connectors can output the data from Kafka topics to the external consumer systems subscribed to those topics 4.

Connect provides the connection to Kafka, but we still needed a source connector. In our research we came across Debezium, an open-source distributed platform that implements log-based Change Data Capture. Debezium offers a number of well-maintained and documented source connectors for use with Kafka Connect. These connectors can be used to capture and create event records with a consistent structure, regardless of the source database.
To our knowledge, Debezium is currently the only production-ready, open-source tool of its kind. Fortunately, Debezium has a strong and active developer community. Although Debezium maintains a number of source connectors, its PostgreSQL connector is one of its core development features and as such was well-suited for our purposes. The Debezium PostgreSQL connector provides built-in support for capturing outbox table changes from the WAL. By default the connector will send all change event records from a single table to only one topic, but Debezium has a ready-for-use outbox event router SMTs (Single Message Transformations) which allow for event records from a single table to be sent to different topics based on the aggregateType. These features and more, greatly simplified our pipeline processes.
Thus, Tumbleweed uses a Kafka Connect instance with Debezium PostgreSQL source connectors to listen to producer service’s WAL to capture every create, update, and delete transaction and pass them to Kafka. They are then passed to our custom-built TypeScript Backend sink which streams the data to the appropriately subscribed consumer services.
4.2.4 Apicurio Schema Registry
One reason Kafka transfers data so efficiently is that it does not perform any data verification on its own, but rather follows the “Zero Copy Principle”, merely transferring data in byte format 5. Thus data must be serialized by producers for transmission and de-serialized either by the sink connector or the consumer. Because Kafka does not perform data validation, a producer could send data in a format which the data de-serializing agent would be unable to handle, which would cause downstream applications and sink connectors to break.
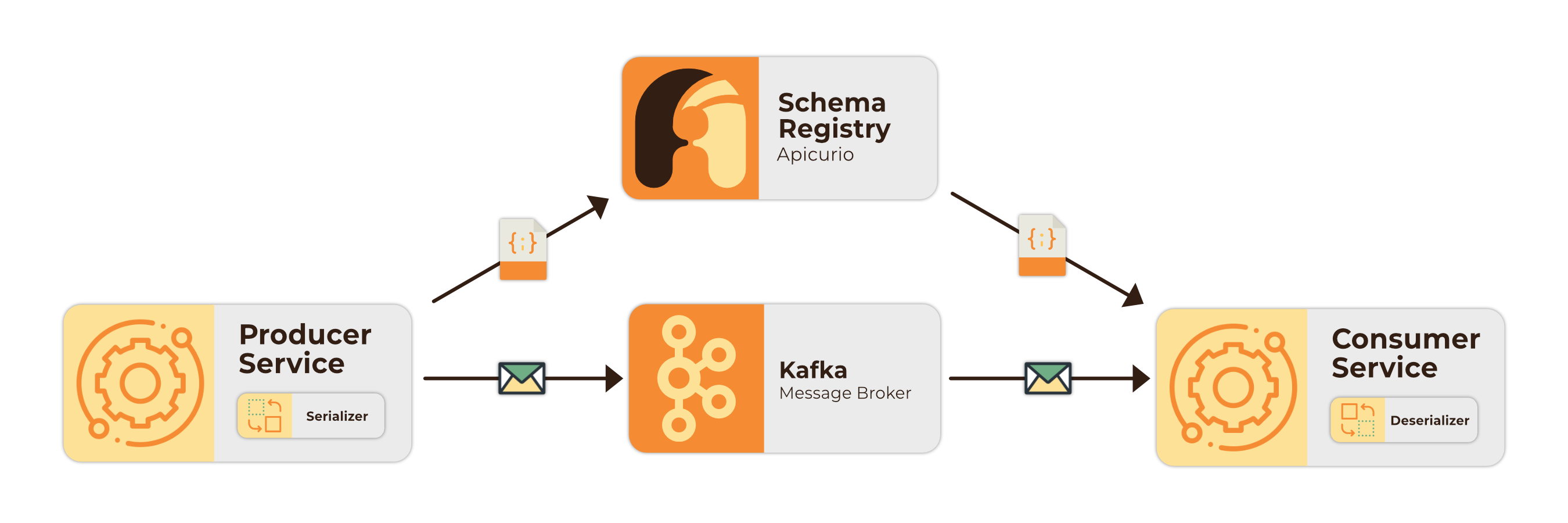
This issue can be alleviated by enforcing the use of specific data formats (e.g. JSON, AVRO, Protobuf) and a data schema (message structure in a given format). However, doing so requires including lengthy schema data in each message passed. A better approach is to add a schema registry. A schema registry is a process external to Kafka which stores and manages the schemas used in a Kafka cluster, requiring messages to only reference a schema ID. Schema registries also allow for schemas to evolve in a centralized manner 6. Tumbleweed uses the open-source Apicurio Schema Registry with JSON Schema for messages passed between Debezium and the Tumbleweed Backend API.
4.2.5 Tumbleweed Backend API (TBA)
Tumbleweed was created with the goal of being user-friendly. In order to achieve this, we needed to create a backend API to perform a plethora of actions on behalf of the user.
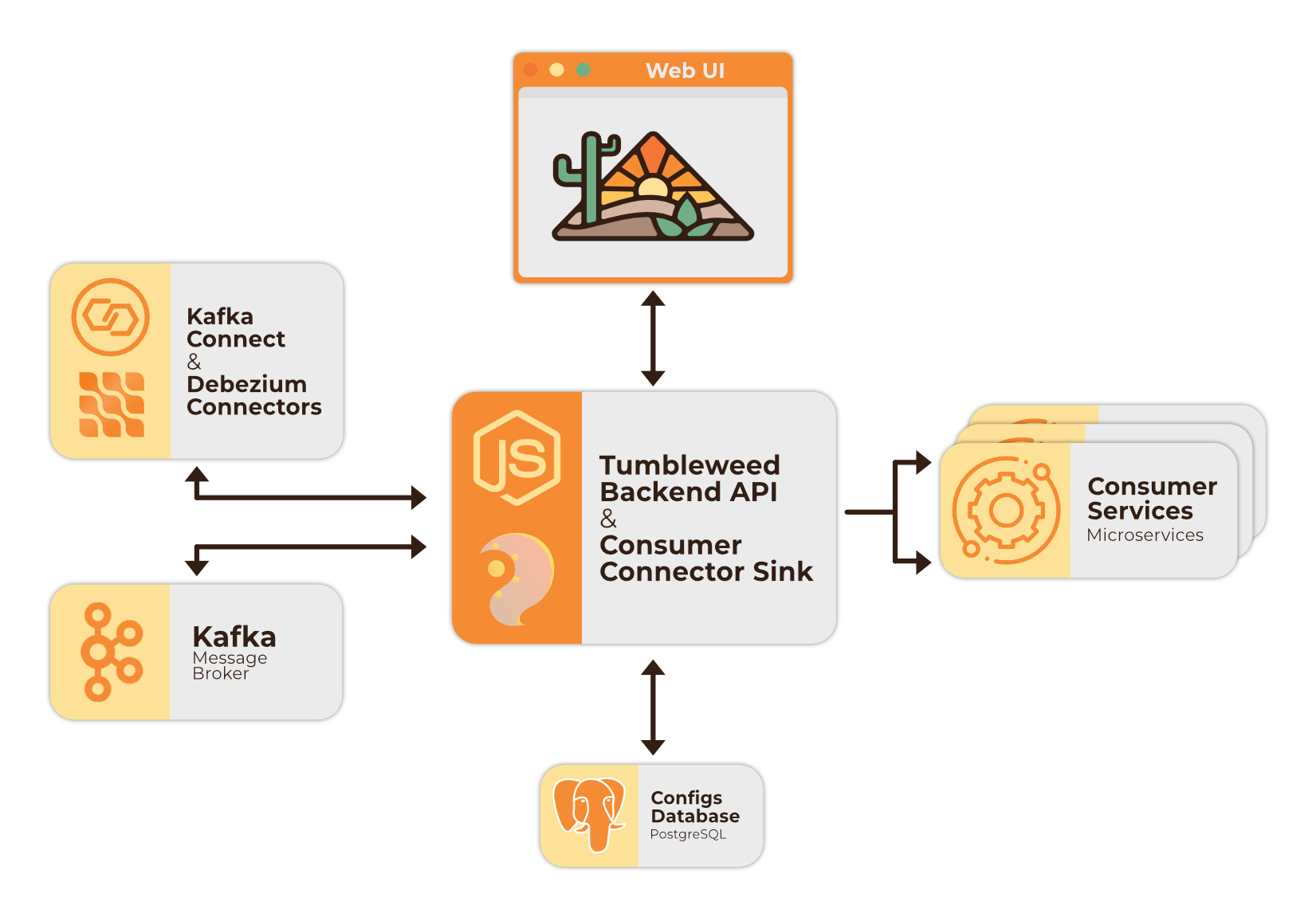
The major actions the backend API performs include:
- Outbox and heartbeat table creation: When a source connector is added for a source database, the TBA creates an outbox and a heartbeat table in that database. Debezium writes to the heartbeat table every 5 minutes to prevent the replication slot from becoming inactive, which can cause undesired WAL-segment accumulation. (See section 6.4 for further details on WAL-segment growth and the heartbeat table.)
- Source connector configuration: Allows for creation and deletion of Debezium PostgreSQL connector instances, with auto-configuration for proper function in the Tumbleweed pipeline.
- Communication with Kafka: The TBA utilizes the Node.JS Kafka client KafkaJS to communicate with the Kafka cluster containers to create, retrieve, and delete Kafka topics and fetch additional useful topic and message metadata.
- Consumer creation and management: Allows for the creation and deletion of consumers which can subscribe to topics. Created consumers are provided a custom Tumbleweed Endpoint URL to implement message stream access.
- Consumer Data sink connectors: Creates custom-built sink connectors which receive data from Kafka and streams it to the appropriate consumers via SSE (Server Sent Events).
- User Interface: TBA serves a front end UI for easy pipeline configuration and management.
- PostgreSQL pipeline data management: TBA stores and retrieves source, consumer, and topic configurations in a user configuration PostgreSQL database.
4.3 Automating Cloud Deployment
A Tumbleweed pipeline is a complex cluster of containerized services. Deployment of such a pipeline can be very complicated with many configuration options. To further simplify pipeline setup, Tumbleweed allows users to deploy pipelines to their own AWS infrastructure via a custom CLI tool and Terraform, an orchestration tool for the automation of virtual infrastructure, which provisions and spins up the system with its necessary settings and software, while also handling versioning, dependencies, and easy teardown.
This process provisions and deploys a cluster of AWS ECS (Elastic Cloud Services) managed containers running on Fargate via the user’s AWS account. Each Tumbleweed user spins up their own private instance of this app which they access from a whitelisted IP address via a provided public URL.
Footnotes
-
M. Kleppmann, Designing data-intensive applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. Oreilly & Associates Incorporated, 2017. ↩
-
J. Kreps, “Benchmarking Apache Kafka: 2 million writes per second (On three cheap machines),” LinkedIn, Apr. 27, 2014. ↩
-
J. Lee and W. Wu, “How LinkedIn customizes Apache Kafka for 7 trillion messages per day,” LinkedIn Engineering Blog, Oct. 09, 2019. ↩
-
L. Cooke, “What is the Schema Registry and why do you need to use it?,” Conduktor Blog, Nov. 24, 2022. ↩
-
J. Pechanec, “Using Debezium with the Apicurio API and Schema registry,” Debezium Blog, Apr. 09, 2020. ↩