2. Problem Domain
2.1 Microservices and Event Driven Architecture
Microservice architectures have become a prominent solution to the difficulties involved in maintaining and scaling large-scale applications. Whereas monolithic architecture functionality is built into a single unit of tightly-coupled components, a microservice architecture separates core functionality into smaller, independent services. These services are typically distributed across a network. This allows for each service to be maintained and scaled independently as needed, which in turn allows for faster development cycles.
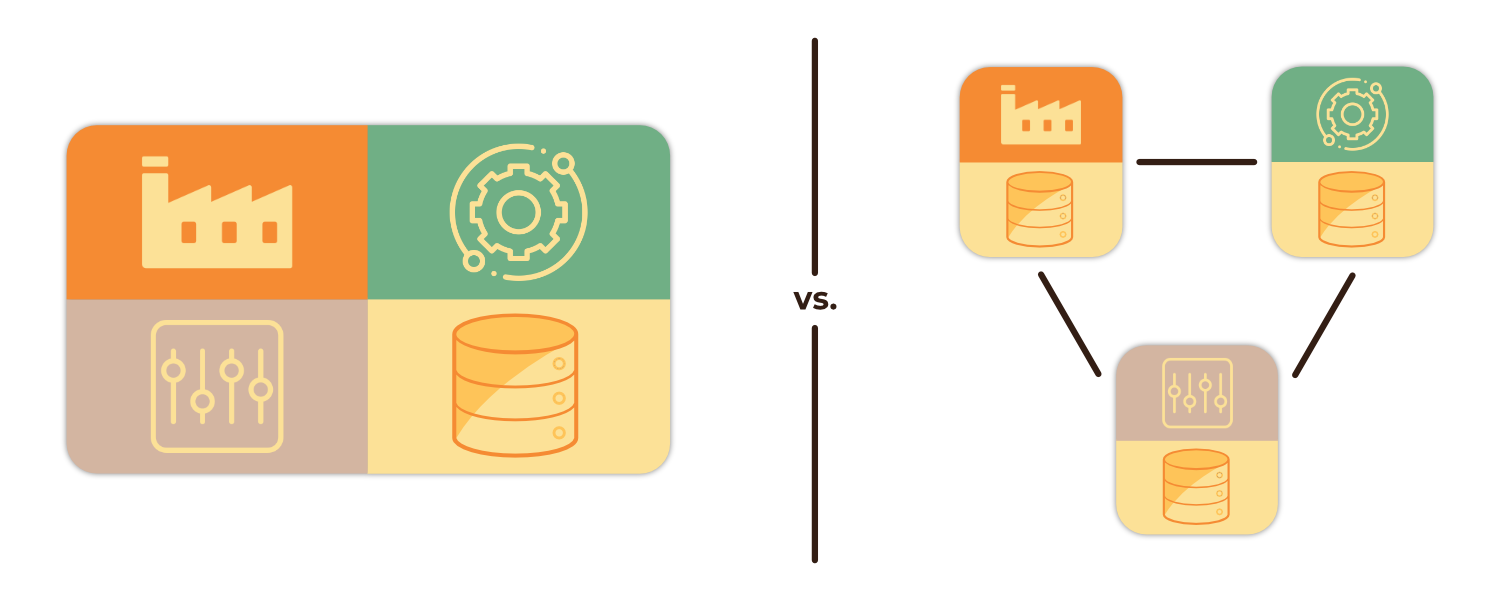
The flexibility and scalability of a distributed architecture introduces additional challenges, particularly in the realm of inter-service communication and data exchange. A good microservice architecture involves the decoupling of services from each other. In other words, services should be as autonomous as possible, with few external dependencies 1. It is precisely this autonomy and loose coupling between services that provides much of the benefit of microservice architectures: allowing for services to fail and/or change in isolation, scale as needed, and more.
Perhaps the greatest challenge then becomes how to exchange data between services under famously unreliable and complex circumstances, while maintaining this autonomy and decoupling 2 3. Services that need to interact are required to update both their own data and propagate this data and/or send notification of the data changes to other services. While this can be done via some manner of synchronous point-to-point API (ex. REST, RPC) between services, such an approach would require the services to be aware of each other to a degree that creates more coupling than is ideal in microservice architectures. Such tight coupling can lead to issues in a variety of ways, such as when a service becomes unavailable, when implementing new services, or when refactoring existing services 4. Additionally, if data is propagated in a synchronous manner, this can become a blocking bottleneck with cascading effects throughout the system.
One solution for this problem is the use of Event Driven Architecture (EDA). In EDA, any “state changes” in a service can also be viewed as events, and records of such events can be sent as messages to be consumed by other services 5. Services that need to communicate assume the role of event producers and/or event consumers. We can further enhance the strong decoupling of this approach by introducing an event stream processing platform to receive data from producers and propagate them to downstream consumers.
2.2 Event Stream Processing and Message Brokers
In event stream processing, an event is a record or "...a small, self-contained, immutable object containing the details of something that happened at some point in time..." 6 and an event stream is therefore an "unbounded, incrementally processed" 6 stream of such data. Many event stream processing frameworks can also be described as asynchronous message-passing systems or message brokers 6. Generally speaking, message brokers allow producing processes to send messages or records to a topic or queue, then the broker facilitates the delivery of that data to subscribed consumers.

The use of a message broker has a number of advantages over direct messaging between services. It can act as a buffer for when consumers are unavailable and more easily allows for a single message to be sent to multiple consumers. This approach also promotes greater decoupling between producer and consumer services, allowing microservices to be designed agnostic as to whom the event data is being sent or how it is being consumed 7. Consumers, likewise, subscribe to only the types of events that concern their business logic and receive these events for processing from the streaming platform.
2.3 The Dual-Write Problem
As we’ve seen, a microservice architecture introduces many challenges related to data management across services and one of the most notable is the dual-write problem.
A dual-write may occur when data needs to be written to different systems. For example, if one service has its own database and needs to propagate information to other services, the data is typically written to the source database as well as another system, such as a message broker, before reaching its destination.
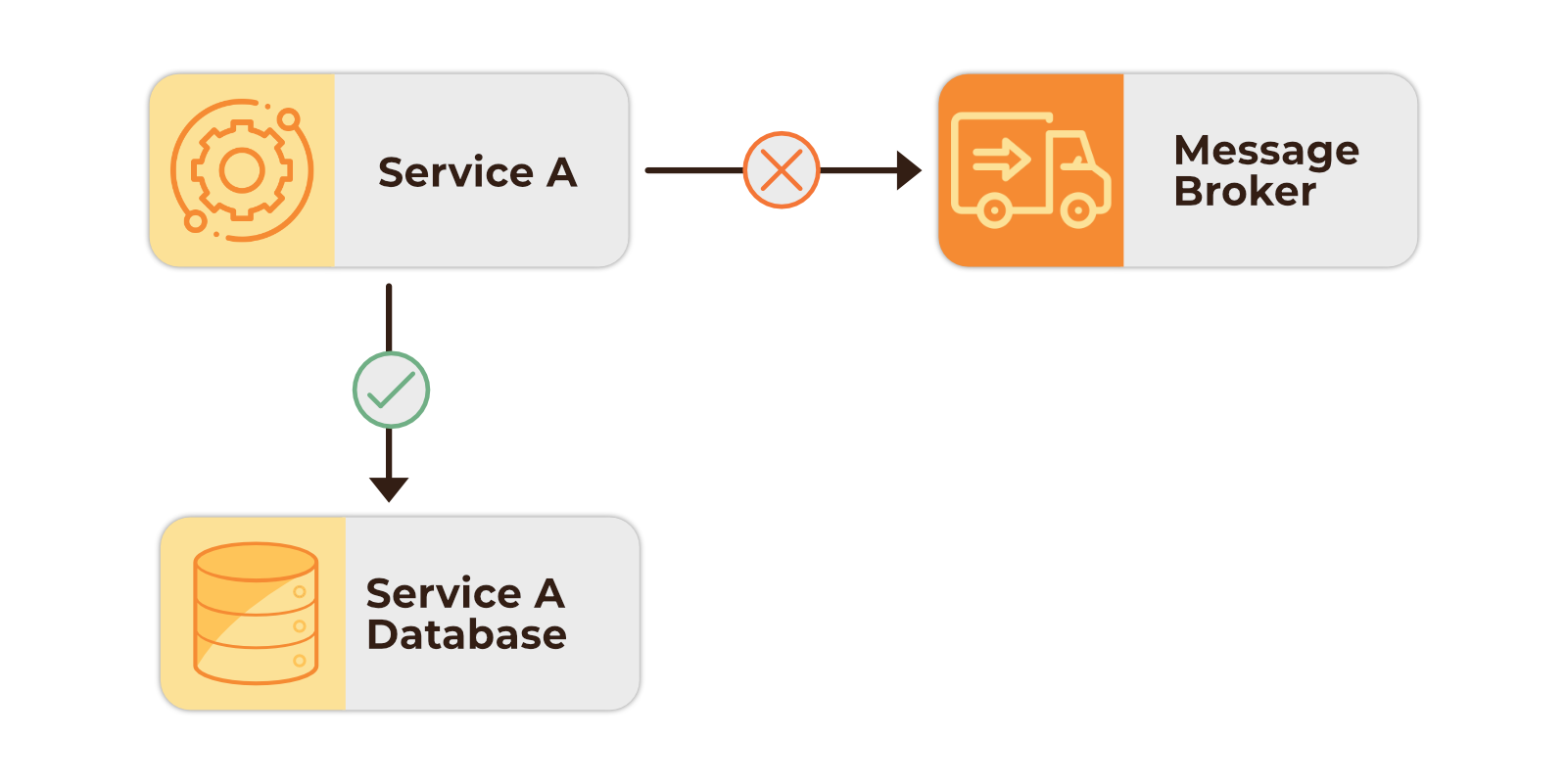
This process of writing changes to separate systems is where problems can arise and create data inconsistencies between services. If the data successfully writes to the source database but fails to be sent to a message broker due to some kind of application or network issue, the source database will have a record of the change even if the destination never receives it.
On the other hand, if the data was successfully written to a message broker, but failed to write to the source database, the destination service received the message but the source database has no record of it. Either scenario can result in errors or data inconsistencies, complicating operations between services.
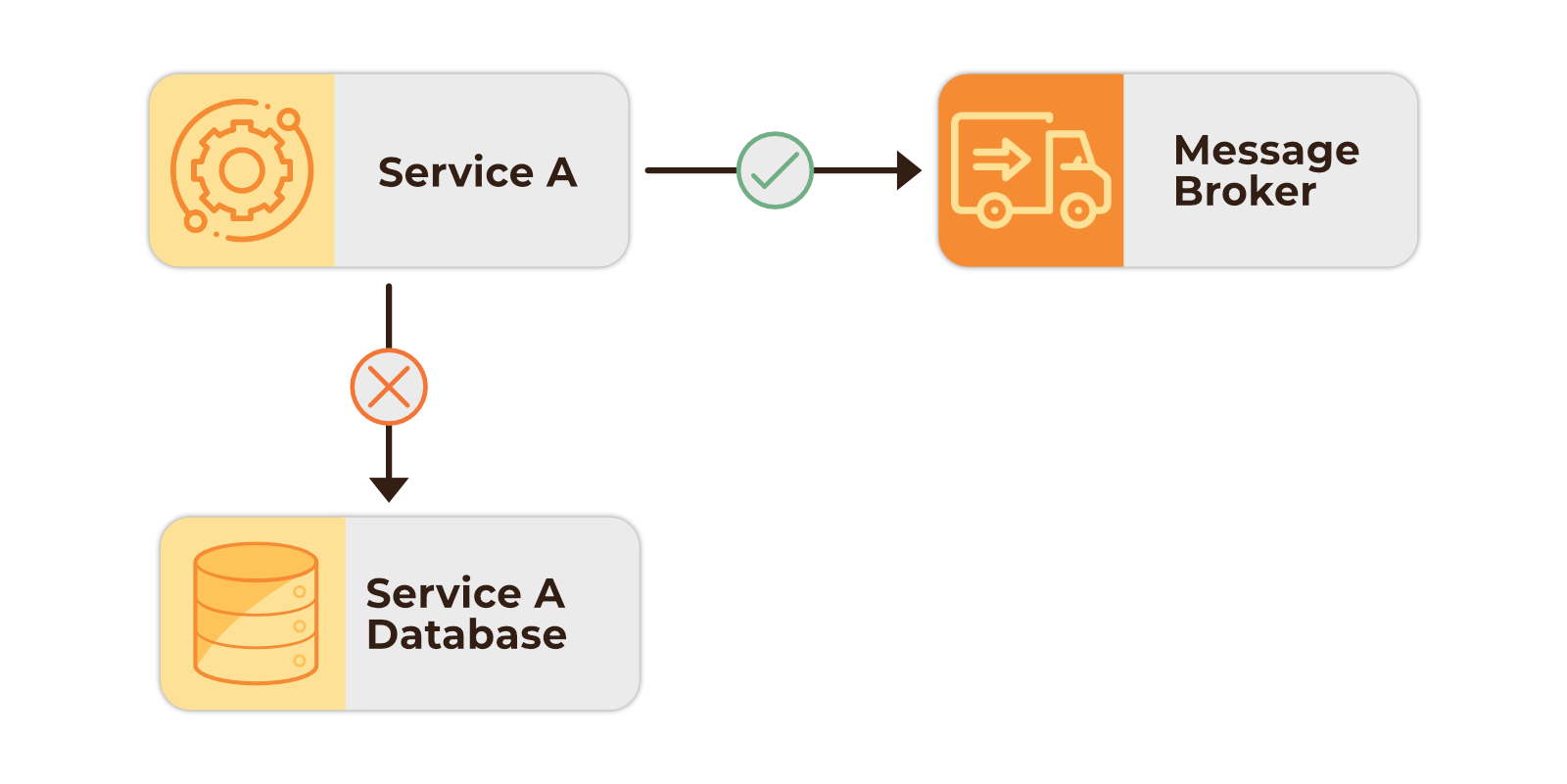
One solution is to only write changes once. If we chose to write changes to a broker, the source service would be listening for new messages, as well as the destination service. When a change occurs in the source service, the message is first sent to the broker before being consumed by both the source and destination services.
This scenario comes with its own drawbacks. While data may eventually be consistent, a source service writing to the broker before updating its own database can introduce latency and create delays, especially if that data needs to be immediately queried from the source database. This has the potential to negatively impact user experience. The handling of delivery failures would also need to be considered. For example, if a message was successfully sent to the message broker but failed to write to the source database for some reason, additional retry logic may be required to address this failure.
Instead, we could write changes to the source database before pushing messages to a broker. For such an approach, a microservice architecture design pattern known as the “transactional outbox pattern” can be used.
2.4 The Outbox Pattern
The outbox pattern ensures “at-least-once” message delivery by allowing for a single transactional write 8. Transactions in a database allow multiple actions to be carried out as a single logical operation. When using the transactional outbox pattern, database changes are recorded locally to a specially created “outbox” table within the same transaction as the original operation. External processes then monitor the database for changes to the outbox table, then create and propagate event records of those changes to downstream microservices accordingly.
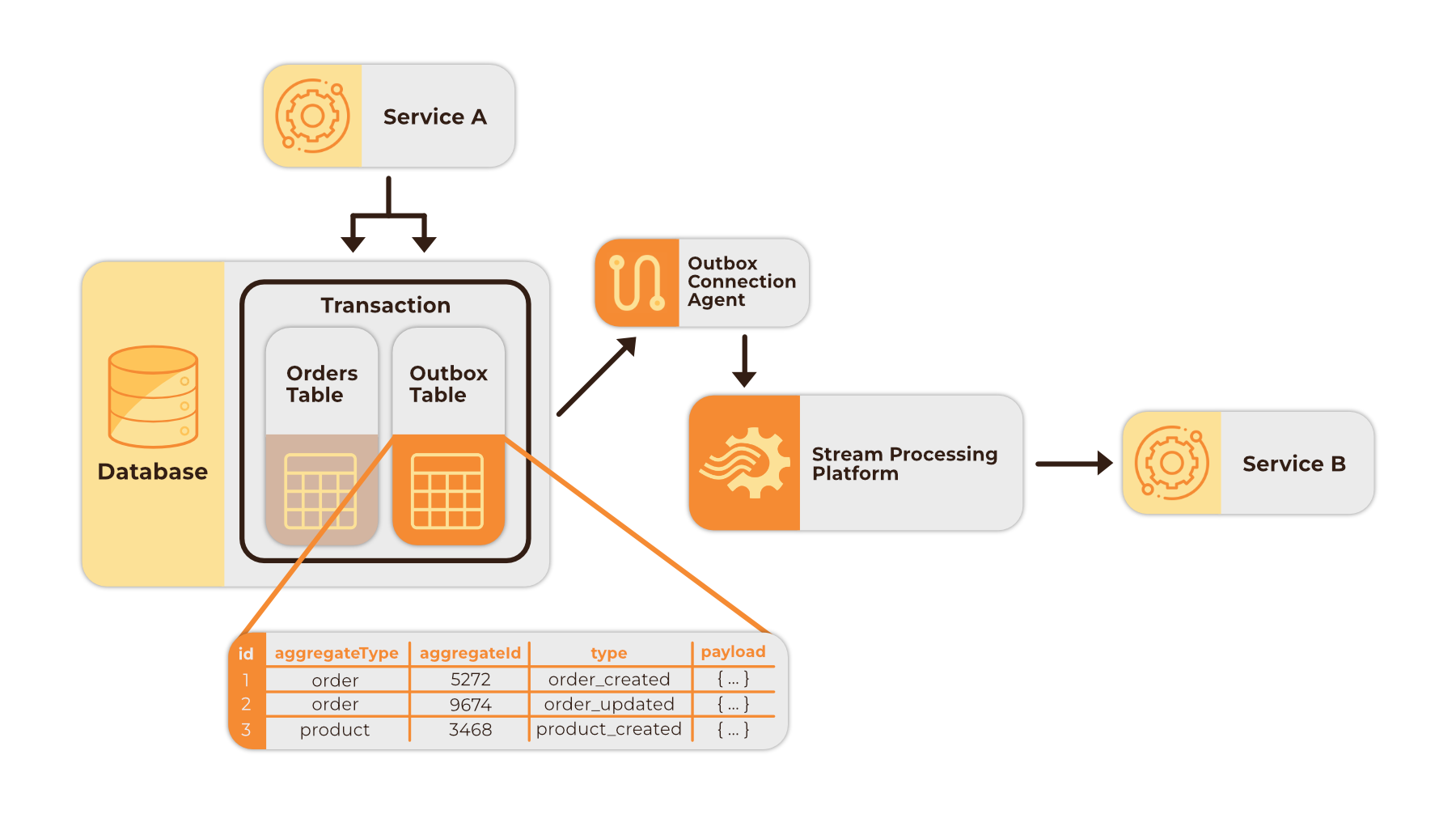
Outbox table schemas can vary but typically include the following columns 4:
id: A unique identifier for each outbox event which can be used by a messaging system for duplicate detection.aggregatetype: An event descriptor, often called a topic, which can be used for categorized routing of event records via a messaging system. For example, In an order propagating service, a change to an orders database might have the aggregate type of “orders”.type: An event category sub-type, e.g. “order_created” which can be used by an event stream processing framework and/or consumer microservices for filtering purposes or triggering various actions.payload: A JSONB object that contains the actual data of the event, e.g. the row-level data change to the orders database.aggregateid: An event key which is the ID of the payload and is used for correct ordering of event records in a messaging system.
The outbox pattern is not only an effective solution to the dual-write problem via a single database transaction, but also includes additional safe-guards for database schemas 9. Since the event record propagation of this pattern relies solely on the structure of the outbox and changes to that table, the entirety of the database schema is never fully exposed to a single endpoint. Each event record contains only the latest insert into the outbox table and these records are only routed to the consumers that require that specific data.
Additionally, as long as the outbox table structure itself remains consistent and insertions are properly handled in the producer service’s code, changes can be made to the service’s database schema without breaking the connection to consumer services or the stream processor 9. For example, columns in an orders table could be deleted or altered, but as long as the rows continue to be added as the payload to the outbox table, propagated events can still be handled without issue. Without this pattern, If we were propagating event records based on the changes to every table, consumers would be required to maintain knowledge of table schemas and have to update their code accordingly for any changes. As discussed previously, such coupling of consumers and producers is problematic in distributed systems, leading to less resiliency. Any database schema changes would likely lead to breaking changes across the propagation system.
The outbox pattern comes with its own potential drawbacks. The most notable being that source services now have to write additional statements to insert data to an outbox table, which could have an impact on latency and throughput. In most situations, this likely wouldn’t be noticeable, but may be something to consider if your application is processing large volumes of data.
2.4.1 Implementing the Outbox: Polling vs. CDC
There are two primary methods for implementing the outbox pattern: Polling and Change Data Capture (CDC). Both methods require creating an outbox table and performing transactional writes to it, along with writes to the other tables that need to be tracked. Both methods also allow for data changes to be passed to a stream processing system or message broker. The difference lies in how the data changes are monitored and propagated to the rest of the system.
When using polling to implement the outbox pattern, background processes query the outbox table for new inserts at a defined interval. When updates are found, outbox entries are marked as processed to avoid duplicate messaging. In such a scenario, the outbox table would need an additional “processed_at” column. These processes will also need error handling and retry logic for when communication with the outbox table fails, ensuring ‘at-least-once’ delivery. However, this approach can be resource-intensive and add additional load to the database. It can also be difficult to determine the correct polling interval, particularly in high throughput data systems where near-real time information is important 10. Perhaps most importantly, this approach can lead to data inconsistency due to missed messages or the inability to guarantee message ordering. If multiple transactions occur in parallel, entry into the outbox table may not be in the same order as the commits 9.
As we will explore in the following section, a simpler, more efficient, and intuitive approach is the implementation of this pattern via log-based Change Data Capture.
2.5 Change Data Capture
Change Data Capture (CDC) is the process of monitoring a source database, capturing data changes, and propagating those changes to a variety of downstream consumers, which may include other databases, caches, applications, and more. In recent years, CDC has emerged as a leading method for near-real time database change propagation in event streaming contexts. There are three primary CDC methods in common usage: time-based, trigger-based, and log-based.

The time-based CDC approach requires adding a modification timestamp column (e.g. “updated_at”) to each table, then polling those tables at regular intervals to track when rows have been altered.
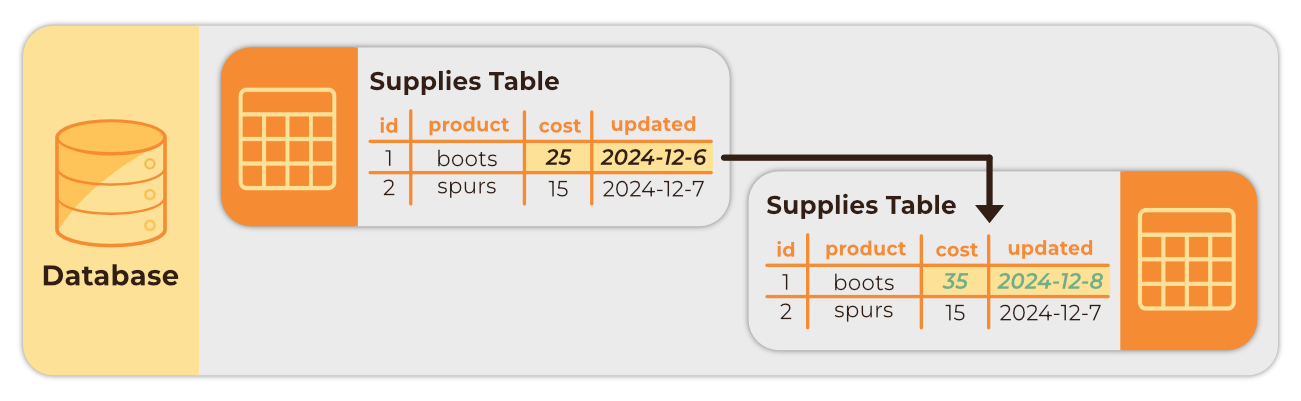
While somewhat straightforward to implement, time-based CDC comes with several disadvantages 11:
- Schema modification: It may be common for a table to have an updated_at timestamp column, but those that do not must be altered, which is not always possible.
- Deletion detection: This approach is unable to detect hard delete operations. Instead of deleting rows, soft deletes can be implemented by adding a deletion indicator column (e.g. “deleted_at”), but this again requires schema modification and can also lead to table bloat.
- Higher latency: Capturing data at intervals may mean the process is no longer occurring in real-time.
- Performance degradation: Requires constant additional database queries which can be a particular burden when dealing with large amounts of data.
The trigger-based CDC approach shares similarities with the polling implementation of the outbox pattern discussed in the previous section and was a prominent CDC method before the development of log-based CDC. It involves using a built-in database function that is automatically triggered whenever an insert, update, or delete operation occurs on a table. These changes are then stored in what is often called a “shadow table”, which can then be queried for data changes for propagation to downstream systems.
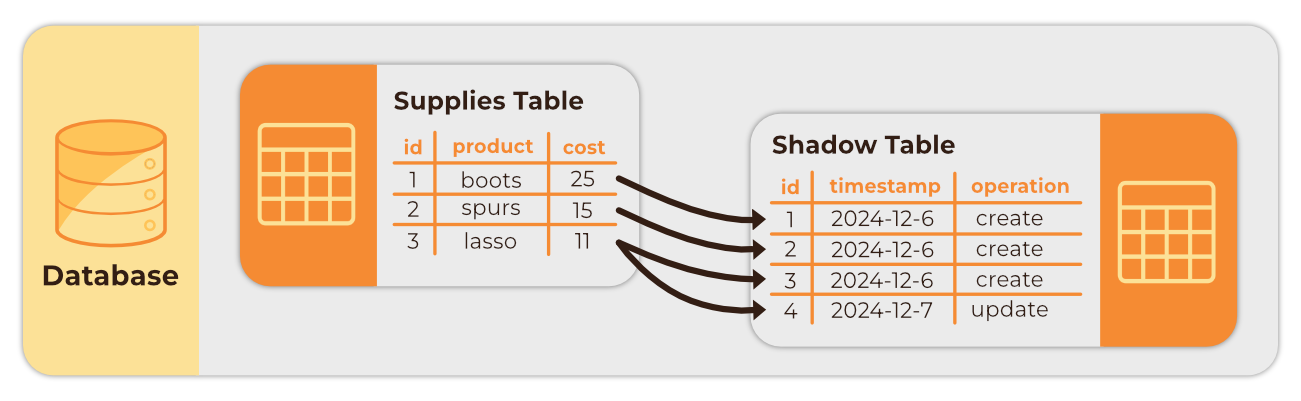
While triggers are supported by most databases, this method also comes with several disadvantages, especially as a database grows larger 12:
- Performance degradation: Multiple writes are required for each operation. This can slow down high-frequency transactions, especially if there are a high amount of triggers.
- Higher latency: This approach can lead to higher latency due to the need for consistent querying of the shadow table.
- Scalability: A large amount of triggers can become difficult to manage.
- Transactional consistency: Multiple parallel writes to the shadow table may result in inconsistent message ordering.
Although both time-based and trigger-based CDC still remain in use, log-based CDC has emerged as a generally more efficient and less invasive technique by capturing changes directly from database transaction logs.
2.5.1 Log-based CDC
For applications that need to access data in near-real time, Log-based CDC is the most widely-used among the various CDC solutions. When changes happen to a database via create, update, or delete operations, the database writes these changes into a transaction log before they are written to the database. This log and its ordering are the source of truth for the database. In PostgreSQL, the transaction log is known as the Write-Ahead Log (WAL). The primary purpose of transaction logs is backup and recovery, but CDC tools have been developed to read from these logs in order to replicate changes and send them to other systems. These tools monitor the database transaction log and when a change occurs, create a record of that change event, and propagate it to downstream consumers.
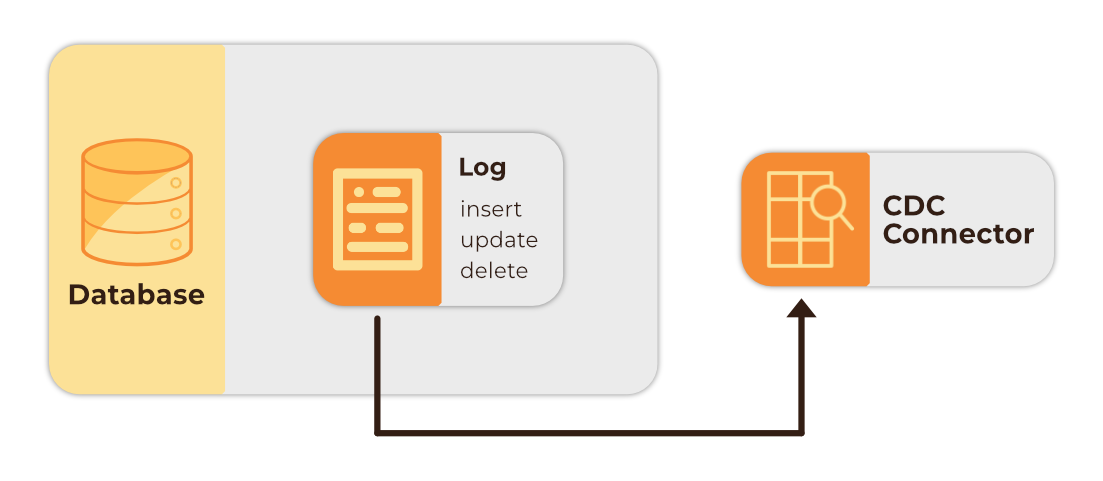
Some of the advantages of log-based CDC include 13:
- Guaranteed in-order delivery: Because log-based CDC relies solely on the log for tracking changes, these changes are received in the same order that they occurred, ensuring data consistency.
- Minimal database performance impact: Changes are read from transaction logs instead of the direct database querying methods employed by other methods.
- Real-time message propagation: Unlike with polling and querying approaches, capturing changes directly from the log allows for near real-time data transfer with minimal delays.
- Low Data Model Impact: As the transaction log automatically records all insert, delete, update operations in a table, database tables do not require modification for use with log-based CDC.
One of the disadvantages of Log-based CDC is that it is highly dependent on the type of source database being used. No universal log format or mechanisms between different types of databases result in less flexibility in CDC solutions.
2.5.2 Implementing the Outbox Pattern via Log-based CDC
Given the benefits and drawbacks of the various approaches discussed above, it is clear why log-based Change Data Capture is a prominent method for implementing the outbox pattern for near real-time data exchange. Insertions to the outbox table are recorded by the database transaction log which is being monitored by an external CDC connection agent watching for changes made to the outbox table. When such changes occur, the agent creates a record of the change event and copies the row change from the outbox table into its payload. This is then sent to an event stream processing platform for further propagation to downstream services.
Footnotes
-
C. Posta, “Why Microservices Should Be Event Driven: Autonomy vs Authority,” Software Blog, May 27, 2016. ↩
-
C. Posta, “The hardest part about microservices: your data,” Software Blog, Jul. 14, 2016. ↩
-
A. Diaconu, “Navigating the 8 fallacies of distributed computing,” Ably Realtime, Oct. 07, 2022. ↩
-
G. Morling, “Reliable microservices data exchange with the outbox pattern,” Debezium, Feb. 19, 2019. ↩ ↩2
-
J. Skowronski, “Best Practices for Event-Driven Microservice Architecture,” dzone.com, Sep. 11, 2019. ↩
-
M. Kleppmann, Designing data-intensive applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. Oreilly & Associates Incorporated, 2017. ↩ ↩2 ↩3
-
“What is event-driven architecture?,” redhat.com, Sep. 27, 2019. ↩
-
K. Grzybek, “The outbox pattern — Kamil Grzybek,” Kamil Grzybek Blog, Mar. 11, 2019. ↩
-
G. Morling, “Revisiting the outbox pattern,” Decodable Blog, Oct. 31, 2024. ↩ ↩2 ↩3
-
“Push-based Outbox Pattern with Postgres Logical Replication - Event-Driven.io,” Lazywill, Oct. 23, 2022. ↩
-
J. Richman, “What is Change Data Capture (CDC)? How It Works, Benefits, Best Practices,” Estuary, Nov. 15, 2024. ↩
-
M. Van De Wiel, “Change data capture: Definition, benefits, and how to use it,” Fivetran Blog, Oct. 08, 2024. ↩
-
G. Morling, “Five Advantages of Log-Based Change Data Capture,” Debezium Blog, Jul. 19, 2018. ↩